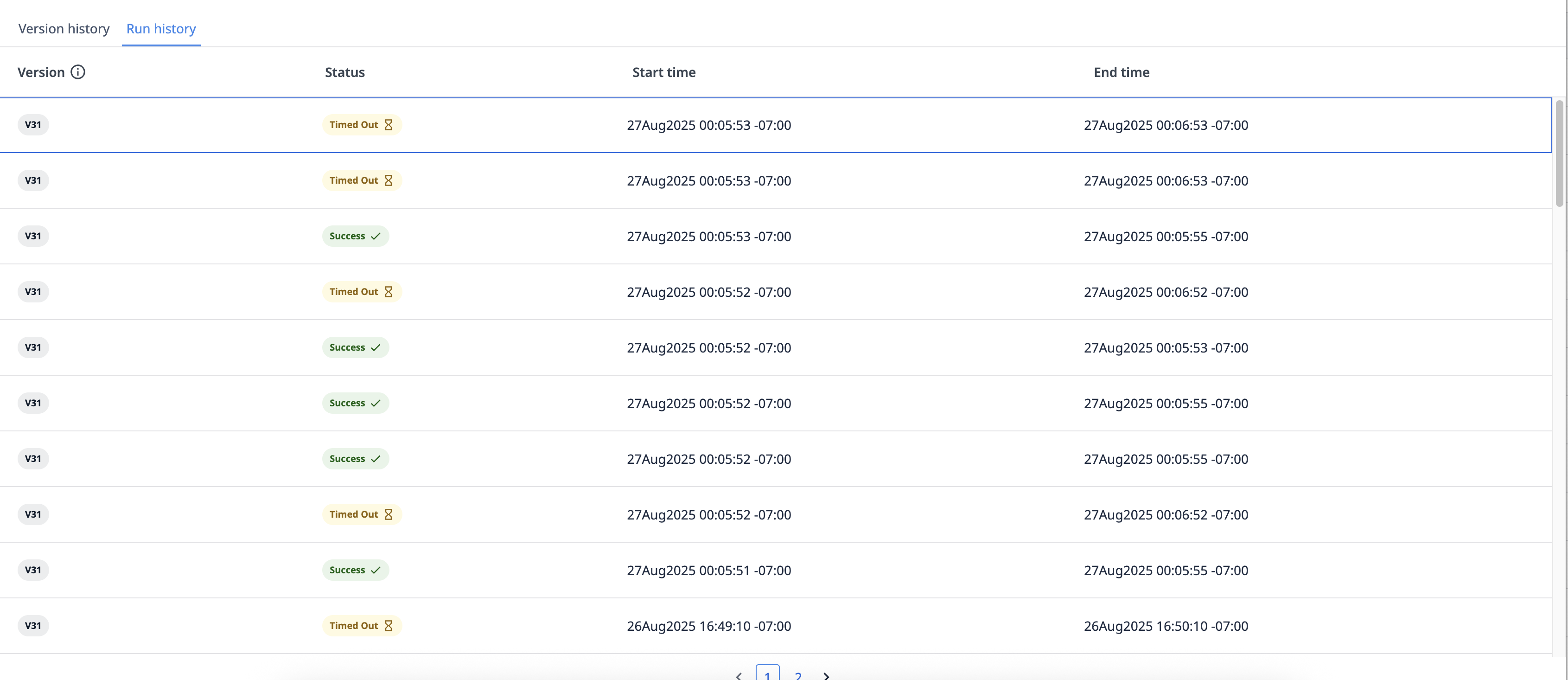
Hello all,
I’ve been running automation for scheduling task for the past month and stressed test it several times and for the past two days it’s been time out for the first time. For context, I expect it to work up to about 30 records of looping at most. But our current test it’s only 5-7 records. Were there any changes in your server or anything that might cause this?
Hello,
Thank you for reaching out about the automation timeout issues you’ve been experiencing. I understand this is concerning since your automation has been working reliably for the past month.
I’ve checked for any recent system changes on our end and haven’t identified anything that would directly cause these timeouts. However, I recently worked on a similar case where a customer experienced 3x slower trigger performance, and we discovered some common causes that might apply here.
Check Automation Execution Limits: Please be aware that Tulip has execution timeout limits for automations. Based on our recent system updates, triggers that run for 30 seconds or longer will now show timeout notifications, and after 10 minutes, they will be automatically cancelled. If your automation is processing 5-7 records and each record requires multiple operations, it’s possible you’re hitting these limits.
Quick Troubleshooting Steps:
-
Browser Dev Tools: Are you or anyone on your team running the automation with browser developer tools open (especially the Network tab)? We’ve found this can cause severe performance degradation - turning 2-3 second executions into 10-13 second timeouts. If dev tools are open, please close them completely and test again.
-
App Versions: Are you running published versions of your apps or dev versions? Dev versions can experience additional performance overhead. If you’re using dev versions, try publishing and testing with a versioned app instead.
-
External Systems: Check if your automation connects to any external systems through connectors or APIs. Have any of those external systems experienced changes or slowdowns recently? Network connectivity issues or slow responses from external services could cause the timeouts.
-
Reduce Batch Size: As an immediate workaround, try reducing your batch size to 3-4 records temporarily to see if that resolves the timeout issue.
Please share the specific error messages you’re seeing when timeouts occur, how long the automations run before timing out, and which Tulip instance and version you’re using. Also let me know if you’ve made any recent changes to your automation logic, connectors, or the systems it connects to.
Best regards,
Nicolo
Hello, from this Automation limits
It mentions that the automation limit is 60 seconds. When was this limit changed to 30s? We did not change anything for the past month and it never timed out. I also stress test this hundreds of times and it’s now live in one of our gmp environment.
Hello chieumaihong,
Thank you for the clarification, and I apologize for the confusion in my previous message. You are correct, the automation timeout limit is 60 seconds, not 30 seconds as I mistakenly stated. I mixed up information from different contexts. The 60-second limit has been in place and hasn’t changed recently. Since your automation has been working reliably for the past month with stress testing and is currently deployed in your GMP environment, the recent timeouts are likely due to other factors rather than a limit change.
Given that your automation was working fine with 5-7 records and even stress-tested with larger batches, let’s focus on what might have changed. A common cause of sudden performance issues is running the automation with browser developer tools open, so please ensure no one is doing this. There may also be temporary performance issues on our infrastructure or your connected systems that are causing slower execution times. Additionally, you should check if any external systems or APIs your automation connects to are experiencing slower response times.
For next steps, can you share the exact duration your automation runs before timing out and whether you’re seeing any specific error messages in the automation logs? Also, which Tulip instance are you on so I can check for any recent performance issues on your specific instance? Again, my apologies for the incorrect information about the 30-second limit. The timeout limit remains at 60 seconds, and we’ll focus on identifying what’s causing your previously reliable automation to now exceed this limit.
Best regards,
Nicolo
Do you guys have any logs on your end regarding the automation run that can help to provide more details of what happened?
Also I want to add that we have 2 instances that run almost identical automation and both failed as well. So that’s the reason why I suspected there’s something happened from the server that ran them. I submitted the Tulip ticket #27895. I would appreciate more brain power to help us troubleshoot this issue.
I hit Run on the API and it does get stalled, sometimes return after a while, and other time time out after 80 seconds.
I then also took a look at all the automation timed out run and it seems that the last step ran was usually right before the Run Connector Function. So that might be a hint that the API call took extra long or never resolved, thus causing the automation to timed out.
us-* |
ARM-based rollout for traefik |
Medium - Brief loss of service (<10 minutes) or significant performance degradation (<30 minutes) |
23-Aug-2025 10:00 PM EST → 24-Aug-2024 02:00 AM EST |
us-14*, us-15* |
PGbouncer configuration change |
Low - No observable impact to service availability |
23-Aug-2025 10:00 PM EST → 24-Aug-2024 02:00 AM EST |
us-15* |
IAM role update for Kubernetes |
Low - No observable impact to service availability |
23-Aug-2025 10:00 PM EST → 24-Aug-2024 02:00 AM EST |
Hello Team,
We first detected the time out issue overlapping with the maintenance event on Aug 24th which is conincide with the maintenance event. I think the PGbouncer is highly relevant to the issue. Would you be able ask your engineer to take a closer look into this?
@chieumaihong @nicolo.lagravinese
We have also faced an issue that had never happened before, but it’s not Automation like mention in this thread, but purely Tulip Aggregation and Query.
We have an Aggregation using calculation Mode, somewhat this calculation stopped working since 21st Aug 2025 in our environment. There’s no changes in our triggers, so we trial and errors with the query filters that make use of this aggregation. ended up , I found the probably cause of it is the limit.
Could you check from your end what has checked since the platform updates in August too? If this should be in a separate topic thread, please let me know! Thanks!